













 Tin tức
Tin tức CÔNG TY CỔ PHẦN DỊCH VỤ CÔNG NGHỆ DATECH

Số 23E4 KĐT Cầu Diễn, Tổ 7, Phú Diễn, Bắc Từ Liêm, Hà Nội

Email: sales@datech.vn
 Danh mục sản phẩm
Danh mục sản phẩm
CÔNG TY CỔ PHẦN DỊCH VỤ CÔNG NGHỆ DATECH
Số 23E4 KĐT Cầu Diễn, Tổ 7, Phú Diễn, Bắc Từ Liêm, Hà Nội
Danh mục sản phẩm
 Bộ lưu điện UPS
Bộ lưu điện UPS 

13/12/2021

13/12/2021
Danh sách nội dung [Ẩn]
Khối lượng công việc AI/ML trong trung tâm dữ liệu tạo ra lưu lượng riêng biệt được gọi là “Luồng con voi”. Lượng lớn lưu lượng truy cập bộ nhớ trực tiếp từ xa (RDMA) này thường được tạo ra bởi các đơn vị xử lý đồ họa (GPU) trong máy chủ AI. Để hiểu lý do tại sao các GPU này tạo ra các luồng con voi này, điều cần thiết là phải hiểu vai trò quan trọng của dữ liệu trong quá trình đào tạo AI, chẳng hạn như mô hình ngôn ngữ lớn (LLM), phân loại hình ảnh, phân tích âm thanh video, v.v.
Trong giai đoạn đào tạo, bước đầu tiên là thu thập dữ liệu thô từ các nguồn khác nhau như Wikipedia, cơ sở dữ liệu cụ thể, lưu trữ đám mây, v.v. Sau đó, các nhà khoa học hoặc kỹ sư dữ liệu xử lý dữ liệu để gắn nhãn hoặc mã hóa từng phần. Sau đó, các mã thông báo/bộ dữ liệu/đầu vào này sẽ được đào tạo để tạo ra kết quả mong đợi. Ví dụ: chúng tôi muốn có câu trả lời có liên quan trong LLM khi chúng tôi nhập truy vấn trực tuyến. Để làm được điều này, chúng ta cần huấn luyện tập dữ liệu, thường lớn và nặng. Vì vậy, chúng tôi cần rất nhiều GPU để huấn luyện mô hình và chúng tôi đang xử lý nhiều hơn petabyte dữ liệu. Thông thường, những dữ liệu lớn/nặng này được chia thành các lô và sử dụng một số cơ chế song song (song song dữ liệu/song song mô hình, chỉ nêu tên hai cơ chế). Sau khi dữ liệu đã xử lý được đưa vào mô hình huấn luyện, cụm GPU sẽ thực hiện các phép tính/huấn luyện số học để có được kết quả mong muốn. Đầu ra của mỗi phép tính đào tạo GPU phải được đồng bộ hóa với các GPU khác trong cụm để có cái nhìn hài hòa. Điều này được thực hiện bằng cách gửi đầu ra của mọi kết quả đào tạo GPU tới tất cả các GPU khác trong cụm. Luồng lưu lượng này (chuyển bộ nhớ) sử dụng các giao thức truyền tải lưu trữ đặc biệt như RoCEv2 và chúng tôi gọi luồng lưu lượng này là luồng con voi.
Để đào tạo các mô hình trên cơ sở hạ tầng phụ trợ AI, Juniper sử dụng cụm GPU để thực hiện các phép tính toán học phức tạp (phép toán dấu phẩy động hoặc FLOPS) và tạo ra lượng lớn kết quả song song; nhờ đó, Juniper có thể tăng tốc độ cung cấp và đào tạo các mô hình AI. Khi chuyển từ công việc này sang công việc khác, gradient/khối bộ nhớ của mô hình đào tạo phải được chuyển từ GPU này sang GPU khác trong cụm để có đầu ra được đồng bộ hóa. Vì vậy, để đồng bộ hóa các kết quả này giữa các máy chủ GPU phân tán, chúng tôi sử dụng giao thức truyền tải RoCEv2, còn được gọi là RDMA qua Ethernet hội tụ – phiên bản 2. RoCEv2 đã trở thành giao thức phổ biến để truyền dữ liệu vì nó không yêu cầu GPU NIC duy trì trạng thái hoặc liên quan đến CPU máy chủ. Do đó, nó có quy mô tốt hơn bất kỳ hoạt động truyền dữ liệu dựa trên TCP nào như NVMEoTCP, vốn chỉ được sử dụng trong các mạng dữ liệu lưu trữ thông thường.
Ngoài ra, sự phát triển mới của sự phát triển phần mềm xung quanh LLM và các mô hình đào tạo theo miền cụ thể khác sử dụng sức mạnh tính toán song song tại các nút máy chủ khác nhau và liên tục đồng bộ hóa trạng thái của chúng trước khi hoàn thành công việc. Điều này dẫn đến việc trao đổi dữ liệu đông-tây với quy mô lớn trên cơ cấu phụ trợ DC trên mạng Ethernet. Vì vậy, chúng ta cần đảm bảo việc sử dụng băng thông vải hiệu quả và hoạt động tốt ngay cả trong các tình huống khối lượng công việc có entropy thấp. Đó là lý do tại sao mạng trung tâm dữ liệu AI phụ trợ lại đảm bảo các đặc điểm sau:
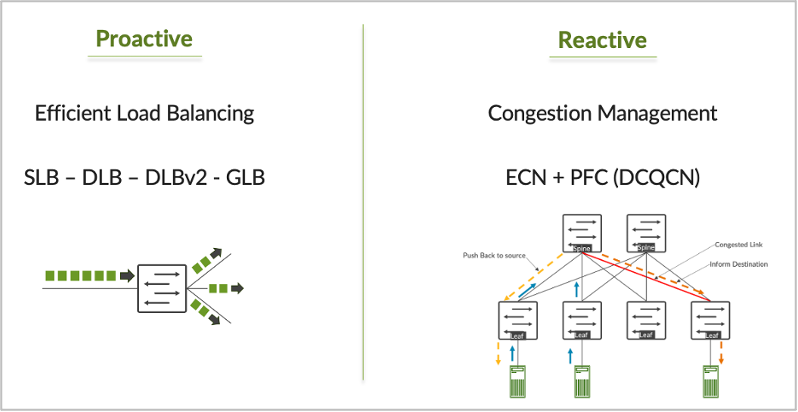
Trong blog này, tôi tập trung vào các kỹ thuật cân bằng tải hiệu quả trong cơ cấu trung tâm dữ liệu AI. Có nhiều cách khác nhau để nâng cao hiệu quả cân bằng tải, một số cách chỉ sử dụng nhận thức ở cấp độ nút cục bộ về chất lượng liên kết và một số cách sử dụng cả hiệu suất chất lượng liên kết cục bộ và nút từ xa để chọn đường dẫn tối ưu. Những kỹ thuật này có thể được phân loại thành bốn cách tiếp cận khác nhau để cân bằng tải:
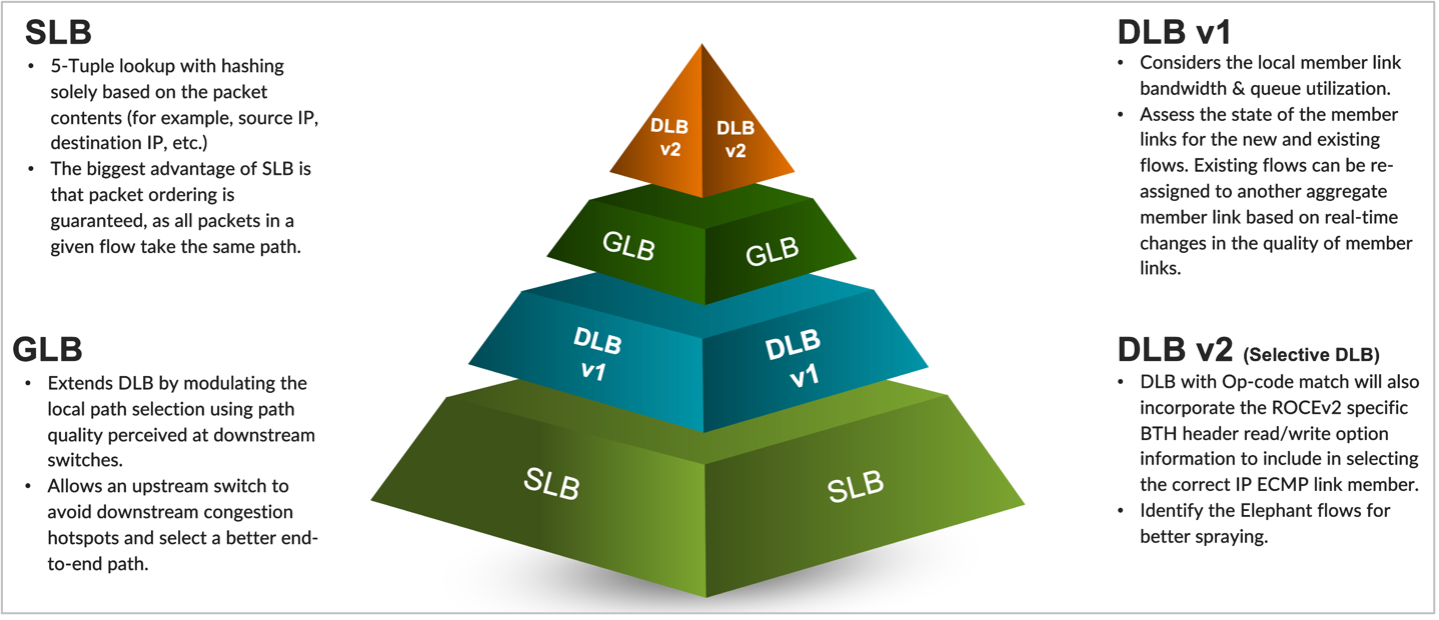
Cân bằng tải tĩnh (SLB) thường được sử dụng trong ngành định tuyến và chuyển mạch Ethernet để cân bằng lưu lượng mạng giữa các liên kết khác nhau và đảm bảo sử dụng băng thông hiệu quả. Nó hoạt động tốt khi triển khai máy chủ truyền thống nơi sử dụng nhiều ứng dụng khác nhau. SLB dựa trên việc tính toán giá trị băm từ các đặc điểm của tiêu đề gói. Trong các khung Ethernet, tiêu đề loại Ether chứa IP nguồn/đích, lớp truyền tải UDP/TCP nguồn/đích và loại giao thức có entropy. Hàm băm cân bằng tải gấp năm lần này có vẻ đủ, nhưng thật không may, nó không phải lúc nào cũng phù hợp với máy chủ AI và lưu lượng GPU RDMA. Lưu lượng RDMA sẽ có entropy rất thấp—có nghĩa là mức độ biến đổi bên trong các gói thấp, khiến các luồng luôn sử dụng cùng một liên kết. Cơ chế SLB không xem xét việc sử dụng băng thông liên kết cục bộ và độ sâu hàng đợi cũng như không kiểm tra tình trạng liên kết trước khi chỉ định luồng cho liên kết. Điều này có nghĩa là một liên kết mang băng thông cao có thể được chỉ định một luồng mới trong khi một liên kết trống vẫn chưa được sử dụng đúng mức. Để giải quyết những vấn đề này, các phương pháp cân bằng tải thay thế có thể cần được xem xét đối với lưu lượng AI và GPU.
Cân bằng tải động (DLB) xem xét việc sử dụng băng thông và hàng đợi của liên kết thành viên cục bộ cũng như trạng thái của các liên kết thành viên đối với các luồng mới và hiện có. DLB có hai chế độ chính: chế độ lưu lượng và chế độ mỗi gói. Khi xem xét việc sử dụng cục bộ băng thông để chọn giao diện nhóm IP ECMP đi, chúng ta phải quyết định xem việc lựa chọn sẽ diễn ra ở cấp độ mỗi gói hay mỗi luồng.
Trong chế độ phun theo từng gói, các gói từ cùng một luồng được phun qua các thành viên liên kết của nhóm IP ECMP. Chế độ này yêu cầu sự hỗ trợ từ NIC để sắp xếp lại các gói tin.
Chế độ cho phép luồng là nơi luồng hoạt động có giao diện đi ra dựa trên việc sử dụng băng thông hiện tại.
Chế độ luồng được chỉ định sẽ cách ly các nguồn có vấn đề. Nó có thể được sử dụng để vô hiệu hóa có chọn lọc việc tái cân bằng trong một khoảng thời gian. Chế độ luồng được chỉ định không xem xét tải cổng hoặc kích thước hàng đợi.
Cân bằng tải trên mỗi gói là một nhiệm vụ đầy thách thức. Quyết định được đưa ra cho từng datagram có cùng luồng tại silicon chuyển mạch và các gói riêng lẻ được trải rộng trên tất cả các liên kết IP ECMP. Ngoài ra, NIC máy chủ cần đảm bảo sắp xếp lại các gói không đúng thứ tự. Ở chế độ Flow-let, thời gian lựa chọn kéo dài hơn và công tắc thường có ít quyết định hơn để thực hiện. Ngoài ra, thẻ NIC trên máy chủ sẽ không phải đảm nhận nhiệm vụ sắp xếp lại.
Khi bộ chuyển mạch được kích hoạt với DLB, nó sẽ duy trì một bảng duy nhất được gọi là bảng chất lượng cổng cục bộ ở cấp độ ASIC và ánh xạ các gói hoặc luồng tới các cổng đi khác nhau. Từ quan điểm của ASIC, bảng chất lượng cổng sẽ được cập nhật thường xuyên dựa trên trạng thái của các giao diện. DLB định kỳ nhận tải cổng và kích thước hàng đợi từ mỗi cổng thành viên trong nhóm tổng hợp. Các giá trị này là đầu vào của thuật toán DLB. Đầu ra của thuật toán là số băng tần chất lượng sẽ được gán cho cổng. Thông thường, có tám dải chất lượng (0-7) được hỗ trợ, với số dải chất lượng “7” biểu thị chất lượng cao nhất và số dải chất lượng “0” biểu thị chất lượng thấp nhất.
Cân bằng tải động là một cải tiến lớn và tăng cường đáng kể việc sử dụng băng thông vải so với cân bằng tải tĩnh truyền thống. Tuy nhiên, một trong những hạn chế của DLB là nó chỉ theo dõi chất lượng của các liên kết cục bộ chứ không hiểu được toàn bộ chất lượng đường dẫn từ nút đầu vào đến nút đầu ra. Giả sử chúng ta có topo CLOS và máy chủ 1 và máy chủ 2 đều đang cố gắng gửi dữ liệu lần lượt có tên là flow-1 và flow-2. Trong trường hợp DLB, lá 1 chỉ biết việc sử dụng các liên kết cục bộ và đưa ra quyết định chỉ dựa trên bảng chất lượng chuyển mạch cục bộ, trong đó các liên kết cục bộ có thể ở trạng thái hoàn hảo. Tuy nhiên, trong trường hợp của GLB, chúng ta có thể hiểu được chất lượng toàn bộ đường dẫn nơi có vấn đề tắc nghẽn ở cấp độ lá gai.
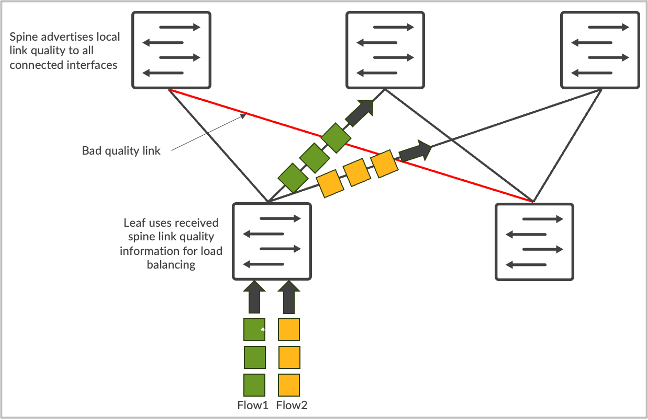
Trong kết cấu trung tâm dữ liệu AI, cách tốt nhất là tạo các bảng chất lượng liên kết từ xa bên cạnh chất lượng liên kết cục bộ. Điều này đặc biệt hữu ích vì các gai tổng hợp lưu lượng truy cập từ nhiều nút lá và sẽ là nơi phổ biến nhất xảy ra tình trạng suy giảm chất lượng liên kết. Thách thức khi triển khai GLB là thông tin phải được cập nhật thường xuyên ở mức micro giây, điều này có thể không thực hiện được khi triển khai kernel dựa trên CPU của giao thức mặt phẳng điều khiển trừ khi nó được phân phối đầy đủ tới ASIC phần cứng của bộ chuyển mạch. Điều này tương tự như việc triển khai BFD trong ngành, phát triển từ việc triển khai phần cứng tập trung sang phân tán hoàn toàn.
Trong tùy chọn DLB trước đó, chúng ta đã thấy các đặc điểm chính của hai chế độ cân bằng tải động có thể có — phun theo dòng chảy và phun theo từng gói. Trong chế độ DLB v2 này, chúng tôi sẽ xác định các luồng và gói phun cụ thể cho chúng. Chúng tôi có thể sử dụng các bộ lọc do người dùng xác định để xác định một luồng cụ thể và ánh xạ các bộ lọc đó vào DLB với kết quả khớp mã Op trên tiêu đề RoCEv2 BTH.
Đây thường là một lựa chọn tốt để có được các cách xử lý khác nhau đối với các gói từ máy chủ, nhưng nó đòi hỏi sự hiểu biết tốt về đặc điểm luồng và một số phân bổ không gian TCAM để cho phép xử lý gói cụ thể dựa trên lối vào được kích hoạt của danh sách truy cập tại bộ chuyển mạch. Như đã đề cập ở phần trước, chế độ gói có thể gây ra các gói không theo thứ tự, điều này có thể không mong muốn đối với tất cả các luồng. Một số opcode nhất định có thể xử lý các gói OOO (có hỗ trợ NIC). Thông thường, quy tắc tương tự có thể được áp dụng cho các hoạt động lưu trữ hoặc đồng bộ hóa dữ liệu cụ thể trong bối cảnh mạng AI DC, trong đó các giá trị opcode RoCEv2 cụ thể có thể được chọn và sử dụng làm tiêu chí khớp ACL để bật một hoặc chế độ cân bằng tải khác. ASIC switch cũng phải hỗ trợ các tùy chỉnh cụ thể và thực hiện hành động từ ACL để kích hoạt các chế độ cân bằng tải cụ thể.
Hãy tóm tắt các phương pháp cân bằng tải khác nhau và so sánh chúng dựa trên khả năng cụ thể của chúng. Khi xem xét các loại vải IP CLOS có tốc độ 400Gbps/800Gbps và sắp triển khai là 1,6Tbps trên mỗi cổng, tốc độ liên kết và cách sử dụng tốc độ này đều quan trọng. Một số phương pháp có thể quan trọng đối với các trường hợp sử dụng cụ thể. Tuy nhiên, những thứ khác ít quan trọng hơn; do đó, một cơ chế cân bằng tải cơ bản như SLB có thể đủ tốt. Tuy nhiên, trong các triển khai phức tạp hơn, chẳng hạn như trong trung tâm dữ liệu AI/ML, DLB và GLB sẽ mang lại hiệu suất chuyển tiếp gói tốt nhất và sử dụng băng thông hiệu quả nhất.
Một số kỹ thuật cân bằng tải mạng AI/ML được đề cập ở trên có thể được kích hoạt song song. Ví dụ: DLB được áp dụng cục bộ tại nút trong khi phân phối GLB hoặc khi nhiều liên kết được bật bên trong một kết cấu cụ thể. Trong quá trình triển khai trung tâm dữ liệu AI, kiến trúc sư mạng có quyền tự do lựa chọn loại hoạt động RoCEv2 (mã BTH) mà phương pháp cân bằng tải nhất định sẽ kích hoạt. Điều quan trọng là phải hiểu rằng hiệu quả của kỹ thuật cân bằng tải phụ thuộc rất nhiều vào silicon. Điều này là do lưu lượng và cân bằng tải phải được thực thi ở mức micro giây hoặc nano giây, đòi hỏi thời gian xử lý nhanh.
Cân bằng tải đã là một thực tế phổ biến trong các trung tâm dữ liệu trong nhiều năm. Điều này là do các trung tâm dữ liệu thường có tính đa dạng ứng dụng cao và số lượng luồng đi vào cùng một bộ chuyển mạch cao, cũng như liên lạc hỗn hợp đông-tây và bắc-nam. Tuy nhiên, các phương pháp cân bằng tải truyền thống không phù hợp với các mạng trung tâm dữ liệu phụ trợ AI/ML mới hơn. Trong trường hợp cơ sở hạ tầng chuyển mạch cụm AI/ML, kiểu giao tiếp điển hình là đông-tây và số lượng ứng dụng chạy trong Ethernet phụ trợ tương đối thấp. Thông thường, chỉ sử dụng phương thức vận chuyển RoCEv2 và không sử dụng phương thức nào khác liên quan đến ứng dụng. Đây là lý do tại sao những phát triển gần đây hơn về cân bằng tải động lại dựa vào việc sử dụng băng thông trên nhóm IP ECMP. Việc sử dụng băng thông cục bộ được sử dụng trong trường hợp DLB, còn cục bộ và từ xa được sử dụng cho GLB. Chúng tôi hy vọng sẽ thấy được nhiều khả năng cân bằng tải tiên tiến hơn trên thị trường trong những năm tới.
Để cập nhật thêm nhiều thông tin, vui lòng liên hệ với chúng tôi:
CÔNG TY CỔ PHẦN DỊCH VỤ CÔNG NGHỆ DATECH




